
第一步 构建DOM树
- 接收到HTML的原始字节
- 根据文件的编码转换成特定的字符
- 将特殊的字符转换成符合W3C标准的各种Token, 例如”html”、”body”等其他标签。每个标签都具有特殊的属性和规则
- 紧接着标签转换为一个可以定义标签规则和属性的“对象”
- 构建出的对象会接着转变成一个个的Node,这些Node包含在一个树数据结构中,这个树可以记录标签的父子关系,以及HTML定义的标签关系,比如HTML对象是body的父节点,body是段落的父节点
- 最终的输出就是DOM,文档对象模型
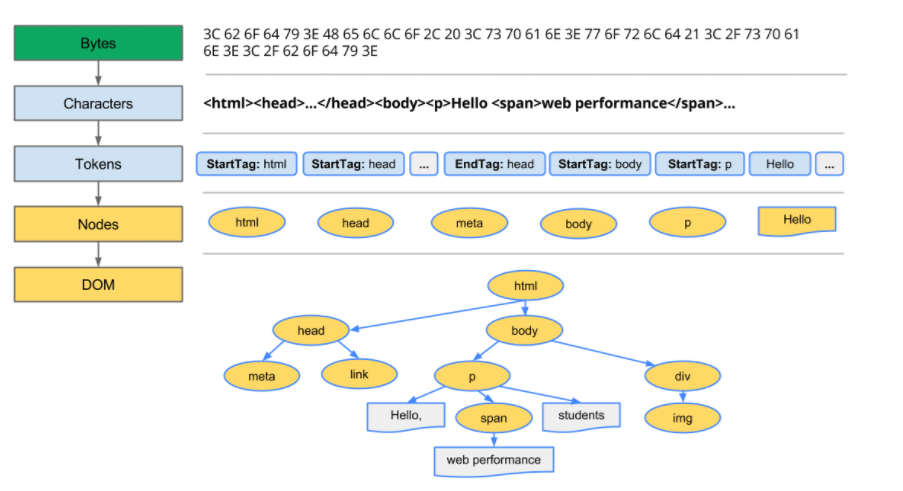
PS:所有的HTML渲染都需要经过以上的步骤
第二步 构建CSSROM树
构建DOM树的过程中如果遇到了link标签,那么浏览器会立即发出一个请求去获取这个文件,然后基于这个文件构建CSSROM。同样的构建CSSROM的时候也需要像构建DOM一样经历一下的几个步骤
最后渲染出来的CSSROM树大概长成这个样子,和DOM树很像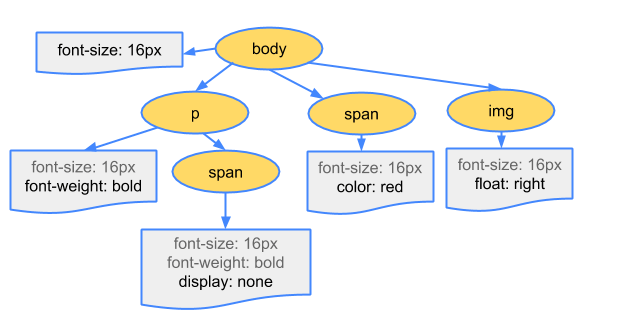
当浏览器为DOM树的每个对象计算样式的时候,浏览器就会从适用这个节点的最通用规则,在树上表现为这个节点可用规则节点中的的最顶层节点,比如在body上设置了一个font-size,那么如果这个节点对象是属于body的子节点对象,那么这个font-size就会被设置上去,然后接着往下找,如果发现这个节点对象本身也设置了font-size,那么这个font-size就会覆盖掉body上的。所以为什么CSSROM也是树结构,因为也是从上到下的去设置样式。
PS: 浏览器本身会提供一个默认样式,这个样式的优先级是最低的,所以如果在树上表示的话,应该就是每个节点对象的父节点
第三部 构建Render Tree
- 遍历DOM树所有的可见节点(某些通过
display: none隐藏的元素会被移除, 而visibility: hidden隐藏的元素依然还会出现在渲染树中,因为它仍然会占据着位置) - 对每个遍历到的节点,根据CSSROM树的规则,为其设置相应的样式
- 把每个处理好的节点,设置到Rrender Tree中
- 浏览器根据得到的Render Tree,计算出具体节点的位置,然后将其中的每个节点转成屏幕上课件的像素
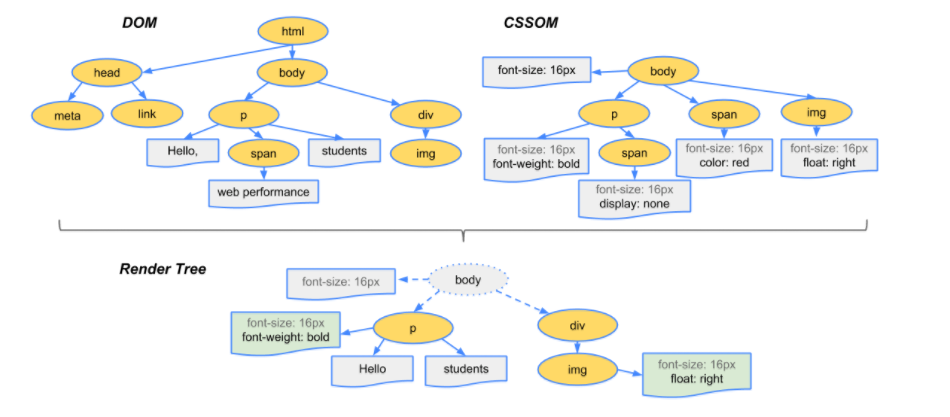
PS: 当DOM或者CSSROM改变时,浏览器会重新执行上述的所有步骤,这就涉及到重绘和回流。后面再来仔细分析分析重绘与回流